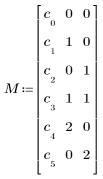
|
Row
|
Description
|
|
1
|
The standard deviation for Y
|
|
2, 3, 4
|
R2, adjusted R2, and predicted R2
|
|
5
|
PRESS—Prediction error sum of squares (useful for scaling residuals)
|
|
6
|
Durbin-Watson test statistic for autocorrelation
|
|
7
|
Matrix of regression coefficients as returned by polyfitc
|
|
8
|
Matrix of ANOVA for the regression model with columns identical to the table of results returned by anova, and with the following rows:
• Regression—Subtotal, which is then broken down for each term (excluding the intercept)
• Residual (Error)—Subtotal, which is then broken down between the Lack of Fit error and the Pure Experimental error
• Total for the regression model
|
|
9
|
Matrix of diagnostics with the following columns:
1. Numbering for each run or data point
2. Observed result for each run or data point
3. Predicted result by the regression model under investigation
4. Residual—Difference between the observed and the predicted result
5. Leverage—Measure of the distance between the observed result and the point that is at the center of all the observed results
6. Studentized residual—Residual divided by the variance based on the observed result
7. R-student—Residual divided by the variance based on a data set where the observed result is removed
8. Cook’s distance—Measure of the influence of the observed result on all the other data points
9. DFFITS—Difference between the result predicted by a regression model based on a data set where the observed result is included and between the result predicted by another model where the observed result is removed
|